こんにちは、SRE の多田(@tada_infra)です!
この記事ではスナックミーのお客様にお届けする,おやつのアサインをカイゼンした話についてです.私と開発者の加藤(id:hisaaki_kato)で記事を書いていきます.
課題とカイゼンの経緯
スナックミーではお客様にお届けするおやつを決めて,専用の BOX に梱包する作業を「アサイン」と呼びます(下記資料イメージ参照).このアサイン工程で事前に○日のアサインはどれくらいの人数に対してどれくらいのおやつを確保しておく必要があるかを計算する処理を「プレアサイン」と呼ぶのですが,この処理がユーザー数の増加に伴い4時間かかる課題がありました.
現状4時間かかるのだからこのままユーザーが推移していけば自然と「プレアサイン」にかかる時間が増えることが予測されます.その分,内部のオペレーション的に①無駄な待ち時間が発生する,②在庫確認するためとはいえ気軽に処理を実行できないのは不都合が多いと言った課題があったので,私と加藤を中心にカイゼンを行うことにしました.
カイゼンの取り組み
次からは具体的にプログラム側で行ったカイゼンと AWS 側で行ったカイゼンを紹介してきます.
プログラム側のカイゼン
プログラム側では、以下のAWS 側のカイゼンで後述しますが、処理を並列化することを念頭にボトルネックとなっていた処理を別リポジトリへと外出しを行いました.
ボトルネックとなっていた処理の概要
一連の処理時間の計測によってボトルネックとなっていた処理は判明しており,DBから取得したユーザー情報をユーザークラスへと格納する処理に全体の8割ほどの時間がかかっていました.アサインを行うための前段階として,ユーザーごとのおやつの好き嫌いやこれまでにお届けしたおやつの評価情報などを格納するだけの処理ですが,ユーザー規模の増加によって指数的に処理時間が増大してしまっていた形です.
必然的に,この部分の処理時間が短縮すれば大幅な高速化が見込めます.そのため,この部分について並列化のために処理の外出しを行いました.
データの受け渡し
処理の外出しに伴い,データの受け渡しを行う必要が生じます.元側の処理ではDBからデータの取得のみを行い,これを外出しした処理でユーザークラスに格納し,再度元側の処理でこれらを受け取って後続の処理をしていくイメージです.ただしユーザーデータそのものは大きすぎて受け渡せないため,S3に保存してそれらのパスをパラメータとしてやり取りする形を取りました.
ファイルの読み書きの高速化
S3へと保存するファイルについては当初はcsvとjsonの形式で保存する想定でしたが,これらファイルの大量の読み書きが新たなボトルネックとなってしまうことが分かりました.そのため,ファイルはpickle形式で保存することでこの部分についても大幅な高速化が実現できました.
AWS 側のカイゼン
AWS 側のカイゼンとして当初 AWS Batch 1台で全て処理したところを、プログラム側で外だしした処理を以下の観点で考慮し Step Functions のワークフローにすることにしてカイゼンを試みることにしました.
- Map を使った並列処理を組める
- 並列処理実行時の成功/失敗のステータスを Step Functions のワークフローで分岐して組める
- AWS Batch にも配列処理があるが,特定の処理だけ並列実行ができなさそうであるため
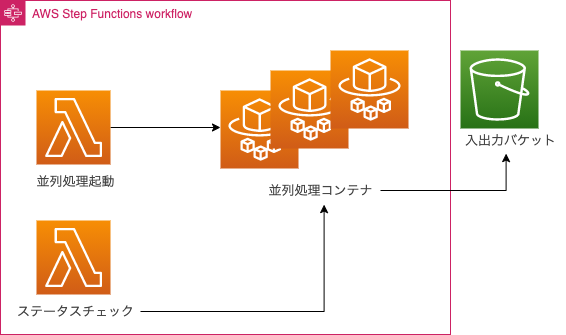
構成イメージ
Step Functions のワークフロー 構成イメージは下記のものになります.ECS Fargate の起動とパラメーターを渡す Lambda と Map を使って多数の ECS Fargate が起動するため各コンテナのジョブステータスをポーリングする Lambda が並列処理の成功と失敗を判定します.Fargate は起動後インプットファイルの取得とアウトプットの出力で S3 バケットを使うような動きをします.
Step Functions の 定義
Step Functions の定義は下記のような ASL を設定しました.最初の Lambda で ECS Fargate を起動して次の Lambda で ECS Fargate のタスク実行状況をポーリングして成功か失敗かを判定する動作をします.60秒待機した後,再度ポーリングし,ジョブが終了していた場合,成功か失敗かを判定するような形です.
ASL 定義
{ "Comment": "Processing ECS Fargate", "StartAt": "test", "States": { "test": { "Type": "Map", "End": true, "Iterator": { "StartAt": "Lambda Invoke", "States": { "Lambda Invoke": { "Type": "Task", "Resource": "arn:aws:states:::lambda:invoke", "OutputPath": "$.Payload", "Parameters": { "Payload.$": "$", "FunctionName": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:run-sfn-execute" }, "Retry": [ { "ErrorEquals": [ "Lambda.ServiceException", "Lambda.AWSLambdaException", "Lambda.SdkClientException" ], "IntervalSeconds": 2, "MaxAttempts": 6, "BackoffRate": 2 } ], "Next": "status Lambda Invoke" }, "status Lambda Invoke": { "Type": "Task", "Resource": "arn:aws:states:::lambda:invoke", "ResultPath": "$.status", "Parameters": { "Payload.$": "$", "FunctionName": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:job-polling" }, "Retry": [ { "ErrorEquals": [ "Lambda.ServiceException", "Lambda.AWSLambdaException", "Lambda.SdkClientException" ], "IntervalSeconds": 2, "MaxAttempts": 6, "BackoffRate": 2 } ], "Next": "Job Complete Check" }, "Job Complete Check": { "Type": "Choice", "Choices": [ { "Variable": "$.status.Payload", "StringEquals": "FAILLED", "Next": "Notify Fail" }, { "Variable": "$.status.Payload", "StringEquals": "SUCCEEDED", "Next": "Notify Success" } ], "Default": "Wait 60 Seconds" }, "Wait 60 Seconds": { "Type": "Wait", "Seconds": 60, "Next": "status Lambda Invoke" }, "Notify Success": { "Type": "Pass", "Result": "Success", "End": true }, "Notify Fail": { "Type": "Pass", "Result": "Fail", "End": true } } }, "ItemsPath": "$.parameter", "Parameters": { "hoge.$": "$.fuga", "s3_bucket.$": "$.s3_bucket" } } } }
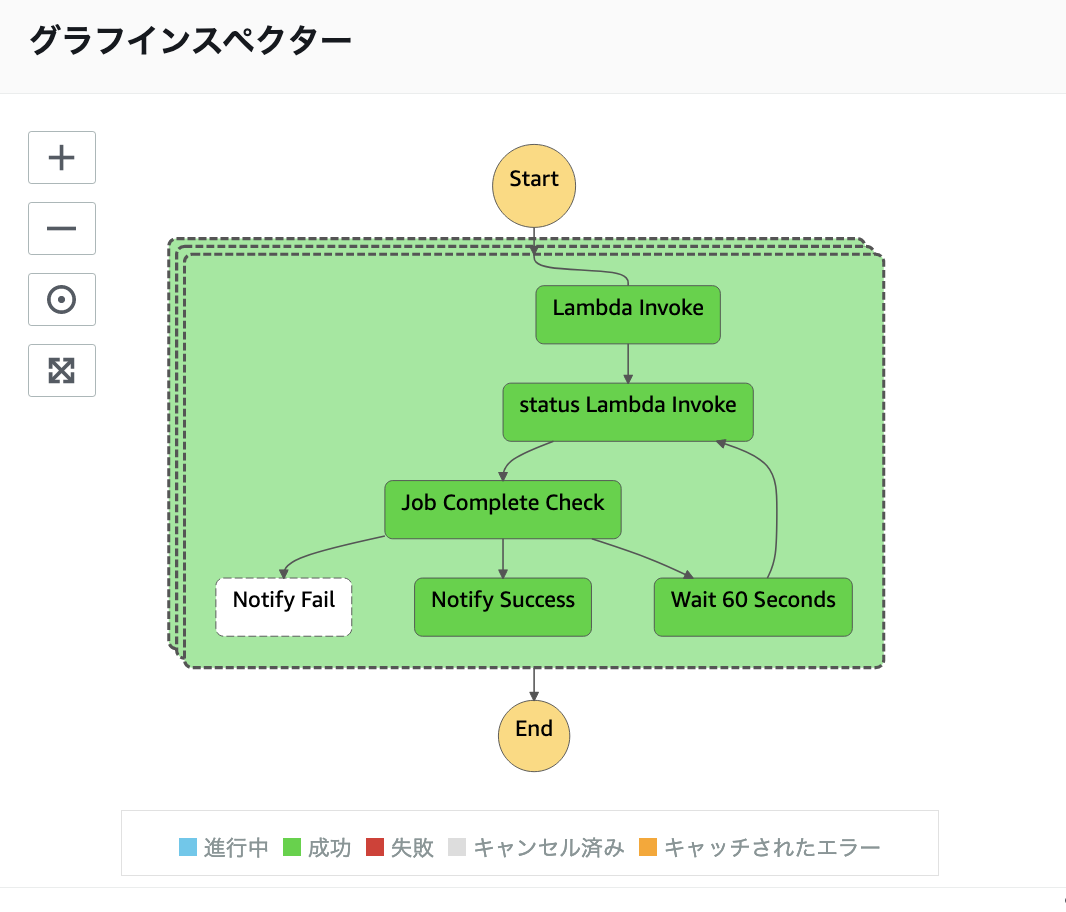
ワークフロー の処理結果確認
ワークフローの処理結果を確認すると以下のようなイメージで遷移し,期待通り動作していることを確認できました.
ワークフロー動作イメージ
一点だけ使っていて注意点があったのですが,Map の同時実行数が40以上を超えるとMaxConcurrencyの注記にもあるように一気に処理しない動作でした.ただ,一気に処理しきれない分も失敗にならず順次実行されるのでこの点を認識していれば問題ないのかなという感想を持ちました.
同時反復は制限される場合があります。この現象が発生すると、一部の反復は前の反復が完了するまで開始されません。入力配列に40項目を超えると、この問題が発生する可能性が高くなります。
40以上実行した場合の処理イメージ(第1弾の処理)

40以上実行した場合の処理イメージ(第2弾の処理)

40以上実行した場合の処理イメージ(最終結果)

まとめ
おやつのアサイン最適化を求めたカイゼンの取り組みを紹介しました.今回のカイゼンですが,検証や本番適用まで3日間に収めつつ大幅な時間の短縮により社内関係者から感謝の言葉をもらえたのは嬉しかったです.これからもよりよい運用の形を開発者と目指していければと思います.