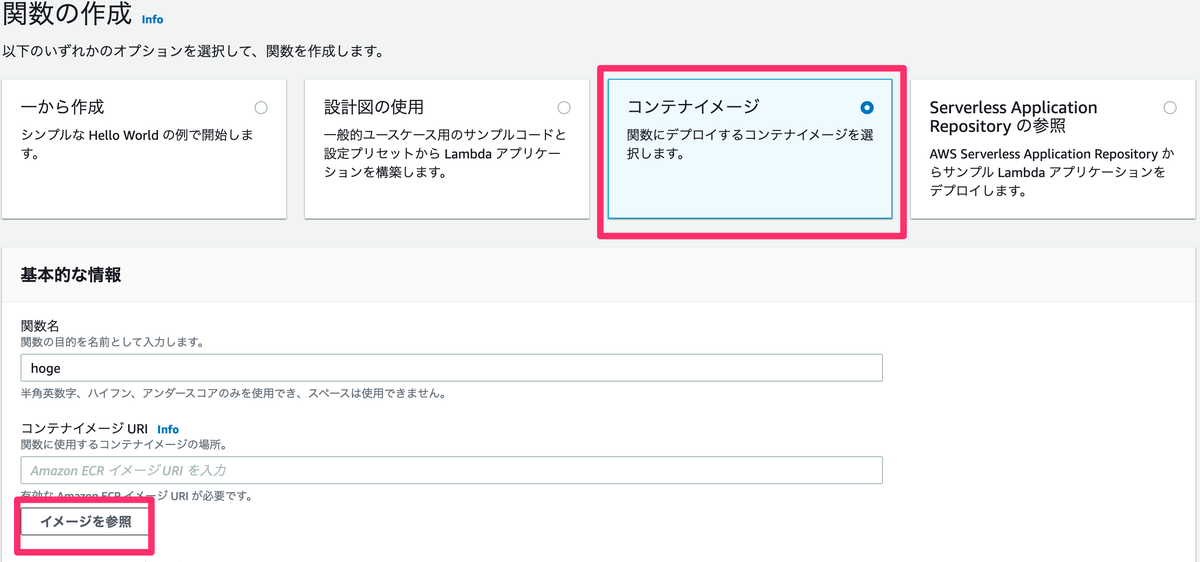
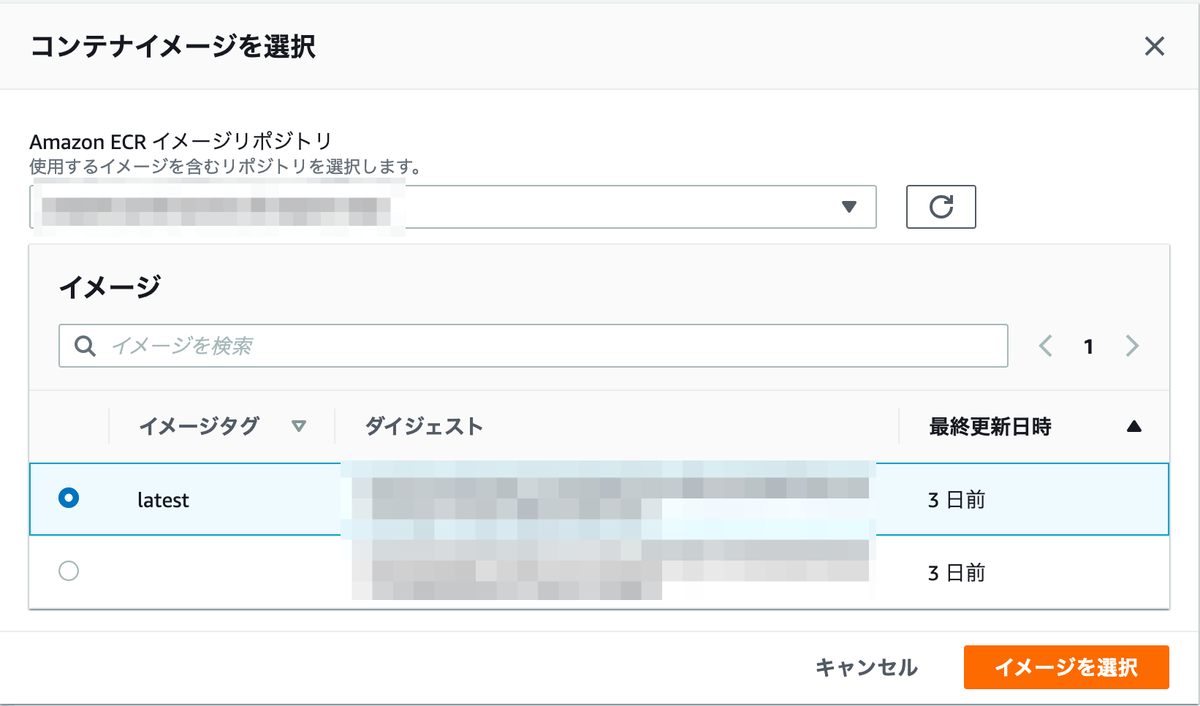
こんにちは!SRE を担当している多田です(@tada_infra).
お客様のおかげで snaq.me はサービス開始から5年が経ちました.これからもサービスのスケールに合わせてシステム側もその変化に対応していけるように既存システムの課題から構成を見直し,改善を試みたのでその模様をこの記事でお伝えしていきます.
既存アーキテクチャにおける課題
弊社のシステム基盤は AWS を採用しておりその上で様々なシステムが稼働しています.これまではお客様への迅速なサービス提供を最優先に取り組んできてアーキテクチャの改善は後手になっていたと思います.私が専任で AWS 周りを管理していく立場で昨年入社し,改めて稼働しているシステムの設定を見た時にいくつかの課題があると感じました.今回は構成変更に伴う部分を抜粋して列挙しますが,大きく2点です.
課題1 VPC にパブリックサブネットしかない
EC2,ECS,RDS,ElastiCache,Lambda,Batch,ELB といった VPC 内に展開しているリソースを配置しているネットワークセグメントがパブリックサブネットでサブネットはそれしかありませんでした.ELB はインターネットから直接アクセスを受けるのでいいのですが,それ以外のリソースは直接インターネットからのアクセスを受けないためパブリックサブネットに配置しておく必要はなかったです.この状態のままリソースが増え続けていたので今後もこのままだと懸念を抱えたまま管理することになるため,本来配置しておくべきネットワークセグメントに移動したいという課題感を持ちました.
改善前の AWS 構成イメージ
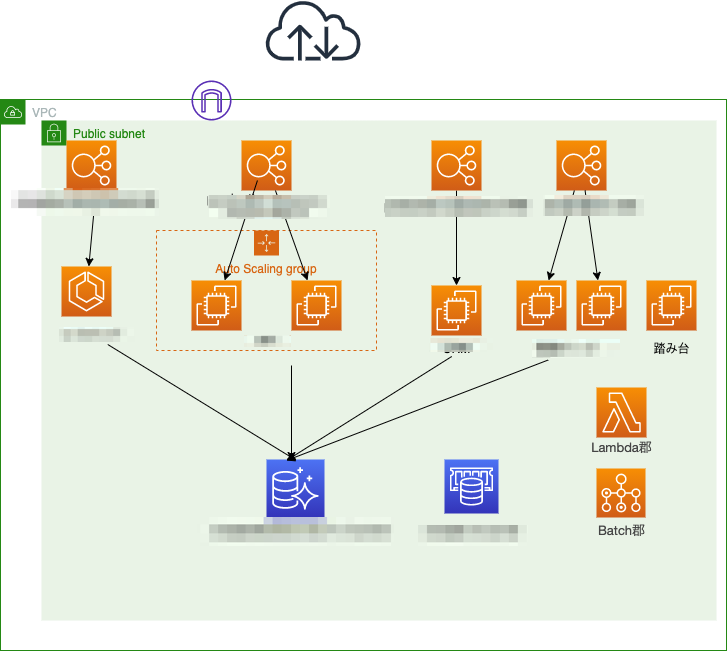
課題2 セキュリティグループの設定の問題
次の課題はセキュリティグループの設定です.セキュリティグループの設定で2つの課題を抱えていました.1つ目は下記のようにインバウンドで受け付けるのがプロトコルがALLだったり,通信元の制御として 0.0.0.0/0 が EC2,RDS の設定で定義されていたままでした.セキュリティグループのインバウンドで受け付けるのにこの定義は広範過ぎるかつセキュリティ的にも突かれてしまう危険性を孕んでいる状態でした.
あるセキュリティグループのインバウンドルールのイメージ
| セキュリティグループのインバウンドプロトコル | IPアドレス範囲 |
|---|---|
| ALL | 0.0.0.0/0 |
| HTTP | 0.0.0.0/0 |
| HTTPS | 0.0.0.0/0 |
| カスタムTCP | 0.0.0.0/0 |
2つ目の課題は上記のようなセキュリティグループが複数のサーバーに跨って設定されていました.例えば,EC2 のセキュリティグループが Lambda,RDS などといった関連ではないリソース間で使いまわされていました.不要なポート開放となるため最低限なポート開放にできるよう1つ目の課題と合わせて解消していく必要があると課題と認識しました.
アーキテクチャの見直しと変更
上記のようなネットワーク設定に起因する課題感からアーキテクチャを見直して変更を加えていきました.
1. プラベートネットワークセグメントの追加
まずはコンピューティングリソースやデータベース郡をプライベートサブネットに移動させたいと思い,サブネットを追加していくことにしました.加えてプライベートサブネットに移動することに伴いインターネットへの疎通のための経路として NAT Gateway や VPC エンドポイントを作ってサービス間通信が継続できるような見直しをかけていきました.見直し後の結果のアーキテクチャイメージが下の図になります.これでパブリックにおいていたリソースをプライベートに配置しなおせました.
改善後の AWS 構成イメージ
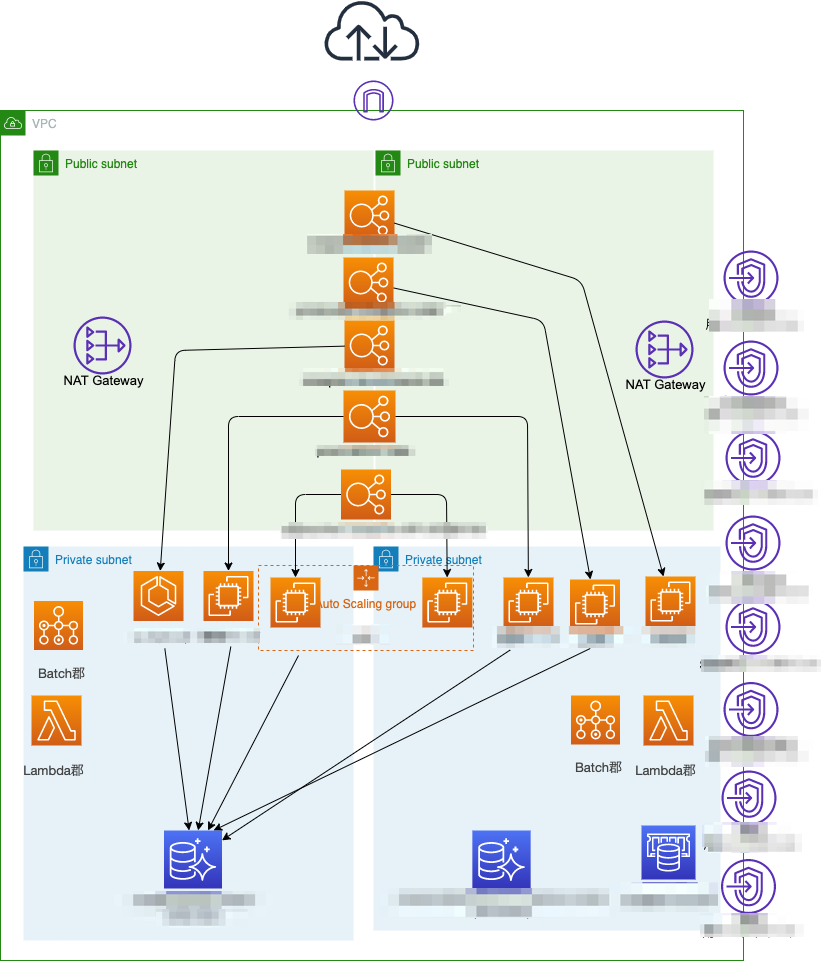
合わせてプライベートサブネットに EC2 も移動したことに伴いこれまでは SSH での接続だったところを Session Manager での接続に全移行しています.また,開発における開発者からのDB への接続は AWS Client VPN 経由でプライベートサブネットの Aurora に繋げるように変更しています.
2. セキュリティグループの作り直しと最適化
セキュリティグループの改善としてサーバーごとにセキュリティグループ定義を作り直して付け直していきました.AWS のサービス間通信はセキュリティグループの ID 同士でインバウンドトラフィックで絞るということもルール化していきました.
改善後の EC2 のインバウンドルールのイメージ
| セキュリティグループのインバウンドプロトコル | IPアドレス範囲 |
|---|---|
| HTTP | sg-xxxxxxxxxxxxxxxx(ELB のセキュリティグループ ID) |
3. 変更の伴う箇所におけるルールをドキュメント化
そして,私が変更をかけた部分について考えをドキュメント化して共有するようにしていきました.私の頭の中にあるだけでは今後メンバーが増えた時に変更をかける時に私がボトルネックになってしまって進めるスピードが落ちてしまうのではないかという懸念から考えを文書化していきました.画像は今回の変更に関わるネットワークのルールを書いたページの抜粋部分ですが,これに限らず今後も設計や運用の考えをドキュメント化していきます.

まとめ
ネットワーク設定に関わる課題感から既存本番システムのアーキテクチャ変更に伴う取り組みをまとめました.個人的には DB のサブネット移行と切り替えのタイミングはドキドキが止まらず,終わった後も数日間業務が止まらないかソワソワしていました.この点,予め影響範囲の確認や取り進め方の相談など CTO 三好のサポートがあり危機的な業務停止はなく動いています.この取り組みでネットワーク周りやアーキテクチャの見直しを図れましたが,他にも課題はあるのでカイゼンをしてよりよいシステムの形を目指していきます.
最後に
そんなスナックミーではもりもりコードを改善し、開発していきたいバックエンドエンジニア、テックリードを募集中です。 採用の最新情報はこちらにありますので、ご興味ある方はご確認ください!