こんにちは! SRE を担当している多田です(@tada_infra).
データの可視化を redash で実現する中で特定のデータが閾値に達した時に Slack に通知して欲しいといった要件があり,redash のアラート機能をその要件に合うものかを検証してみたのでこの記事に検証した内容を整理してきます.
検証で使った環境
検証で使った環境は redash の AMI を使っています.東京リージョンのものを使ったので ami-060741a96307668be を指定しています.
redash アラート機能設定
今回のケースではデータがリアルタイムで更新される社内システムがあり,そのデータを redash からクエリを発行して見たいといった条件を想定した検証しています.検証した内容にフォーカスするため redash の初期セットアップやデータソース,アラートに関連するクエリ結果の事前設定は割愛し,設定済み前提でアラート機能を使うために設定した内容を以下では書きます.
Slack の設定
まず,アラート発生後の通知先として Slack に通知したいので Slack の設定からです.Settings > Alert Destinations > New Alert Destinationから Slack を選択します.
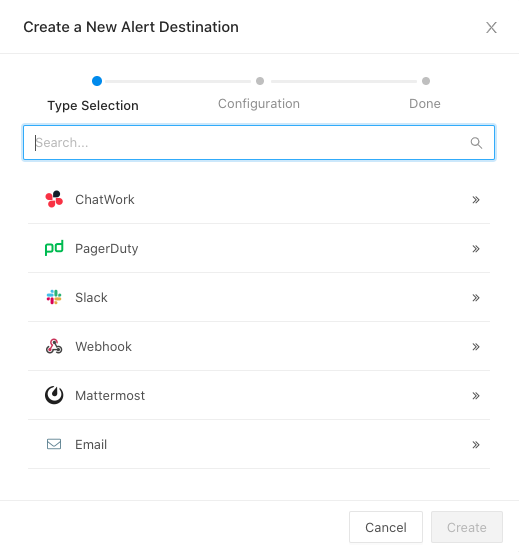
次に, Slack 自体の設定ですが設定名と Incoming Webhook URL を設定しました.
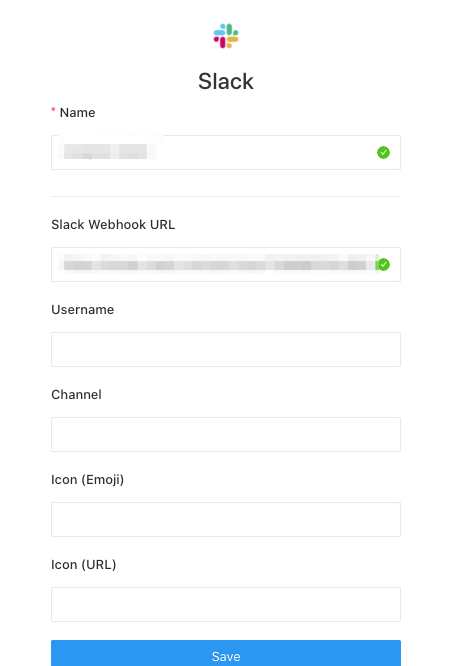
以上でアラート先の設定自体は完了です.
アラート設定
そして,アラート設定に移っていきます.上部メニューのCreate > Alert を選択します.
- 最初にQuery 欄に事前定義したアラートに関連するクエリを選択します.
- 次にアラート通知したい結果が入っているカラムを指定します.
- そして,アラートの条件を指定していきます.今回は Value が 100 以下になった時にアラートを出すよう設定しています.
- 最後に先ほど指定した Slack の設定を通知先から選んで Add で追加し,Save ボタンで保存します.
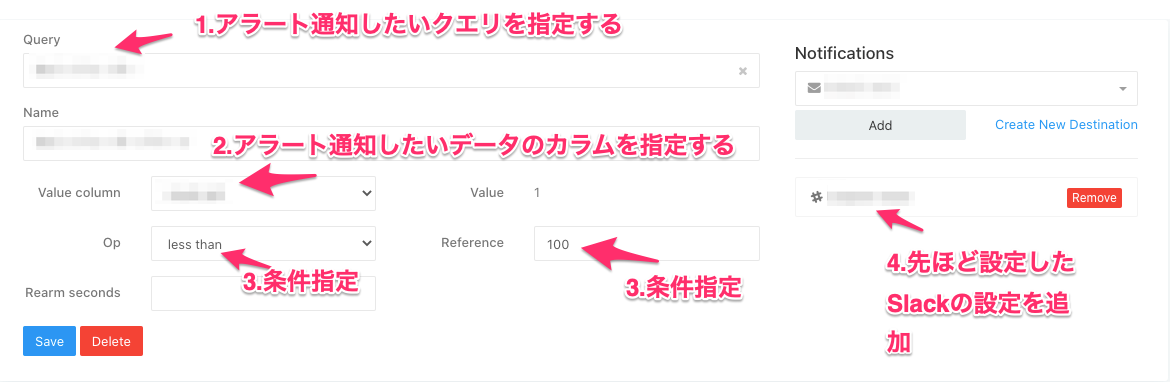
以上でアラート設定が完了です.
Slack への通知結果
あとはデータが閾値に達するまで待つだけですが,閾値に達した時に以下の画像のように通知されます.このような形で Slack へのアラート投稿ができました.

設定中に感じた注意点
設定自体は完了なのですが,redash のアラート設定を試して感じた注意点を最後にまとめます.
- アラート通知できる条件で指定できる値は1つだけなので,クエリ結果で複数レコードが返る場合1レコードしか返らないようにしないと意図したアラートは発行が難しい
- 画面上で確認する限り条件分岐ができるわけではなさそうなので複雑な処理する場合はコードで制御が必要になると思われる
まとめ
redash のアラート機能で Slack 通知する設定を検証したのでまとめました.クエリの結果を1つに絞れればリアルタイムでコードを書くことなく通知できたのは手軽に設定できてよかったなという感覚でした.
元記事
元記事はこちらです.
最後に
そんなスナックミーではもりもりコードを改善し、開発していきたいバックエンドエンジニア、テックリードを募集中です。 採用の最新情報はこちらにありますので、ご興味ある方はご確認ください!