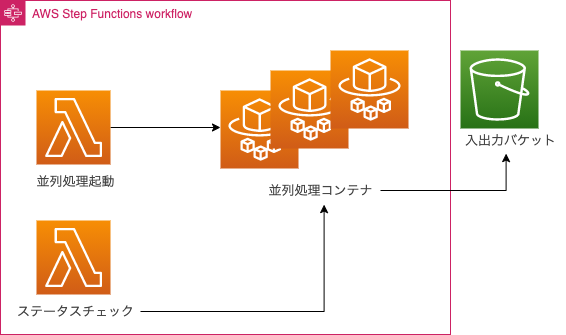
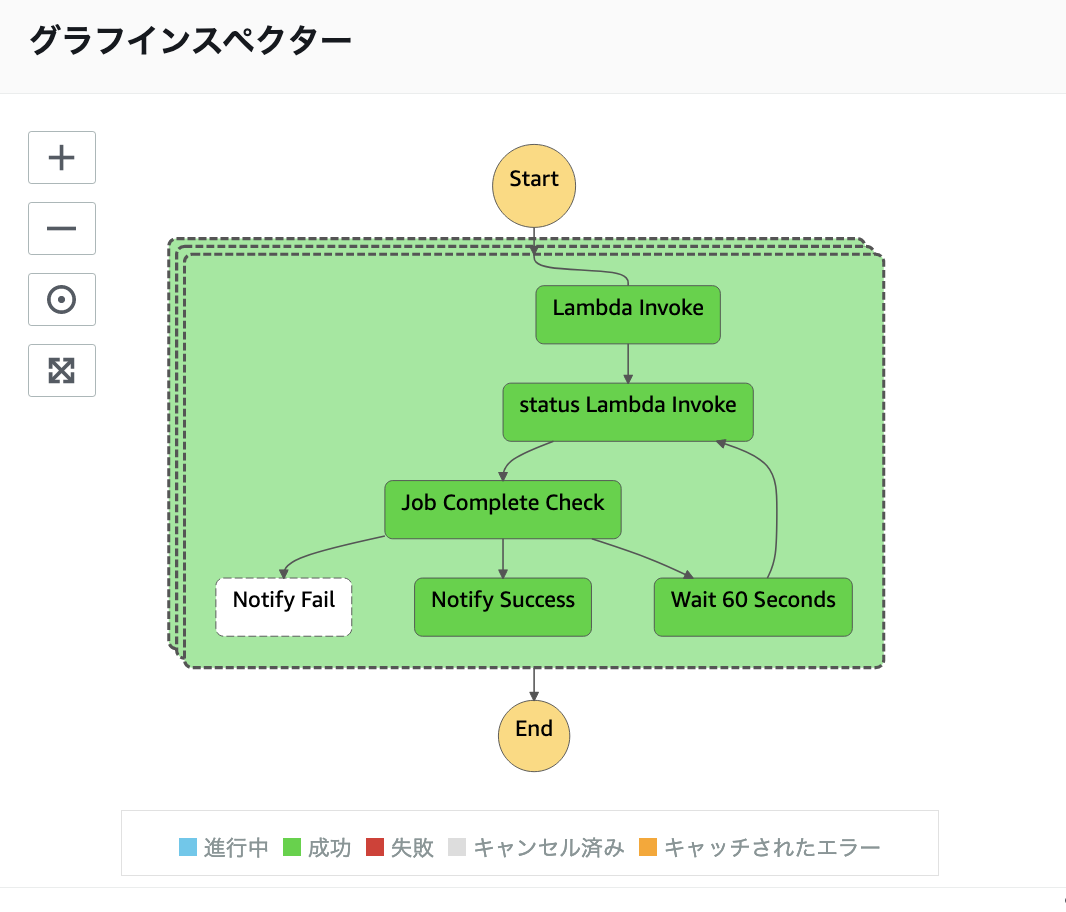
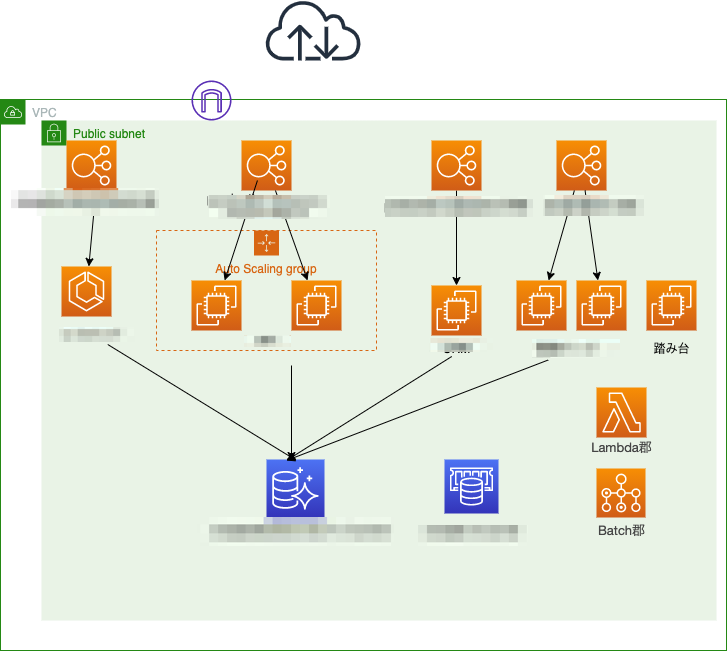
こんにちは スナックミー CTO の三好 (@miyoshihayato) です
四半期ごとにチームに共有している直近動いていきたいことを一部変えてこちらのエンジニアブログに載せたいと思います。
歩み寄りの意識
スナックミーにとってエンジニアが開発することで全体が前進できる部分が多く存在しています。(おやつ選定のアルゴリズム、出荷システム、LINEやメールを用いたCRM、おやつのリクエストなど)
一つの機能、1回の分析、パフォーマンス改善全てが無駄なことなんて1つもなく、何かしらプラスに起因してます。
よりプラスに働くには、互いに(エンジニア同士、他チーム)押さえ合うのではなく、良い方向に引き合う関係である必要があると思います。
そのためにも、ただ要望を受け対応するだけではなく、相互に高め合えるような姿勢を意識したいと考えています。
そこで高め合えるためには互いに歩み寄りの意識が必要だと思っています。
完全に任せっきりにするのではなく、少しでも知っていく姿勢 (100知る必要はなく、1でも知ろうとする動き)
1 知っている状態と知らない状態では議論の深さが違いより良質なアウトプットになると思っています。
また、知っていくことで開発も相手の目線で提案・開発ができるようになると考えています。
非エンジニアから見るとエンジニアがやっていることは一番ブラックボックスに近い仕事かと思います。UI/UXなど目に見えるものは認識されやすいが、それ以外のことはなかなかイメージしずらいため、何をしているのが話してもよくわからない。
そのためエンジニアから歩み寄ることで認識できる部分があるはずなので、この実践をエンジニアチームではやっていきたいと思っています。
仕様追加 と 仕様変更 (改善)
機能の要望をもらうとき、追加と変更・改善を一緒に考えて対応している場合はないでしょうか? それぞれの立ち位置を考えないと、システム全体が劣化していく可能性があります。 (リファクタしていく話とは違う話です)
仕様追加
仕様追加は現時点から
プラス+に寄与マイナス-に転じる
にもなりうる
例えば、ある商品登録するシステムにおいて必要だと認識していた1つの機能を追加されることは、数年前から利用している人にとって学習コストはさほど上がらず、便利になったと感じることが多い。
一方、これから始める人(始めたての人)にとってこの追加機能は追加されたことで学習コストを数倍にも膨れ上がる可能性があります。
(将来的には属人化さ理解すらできなくなる)

仕様変更 (改善)
一方でこの仕様変更や改善は
マイナス-から0orプラス+プラス+から プラス+α
全方面にとってプラスに寄与することが多い
マイナスに寄与する可能性がある場合は A/Bテストなどで検証は必要になる

毎回問いたい
追加要望がNGと言っているわけではなく、本当に必要なことって何なのか?ということです
追加の場合
- 解決したいことは何か
- 本当に追加する必要性があるのか
- 追加することによって紛らわしくなってないか など
変更・改善の場合
- 何を良くしたい(ペイン)のか
- 何が良くなるといいのか
- 変更の場合、利用者が混乱する時があるので許容範囲なのか など
考えて実装できるように、
コードが書けるだけのエンジニアになってほしくないそんな思いが強いです。
しかし、深く考えすぎて何もできなくなると元も子もないので、シンプルにすることを忘れないようにしたい。
開発から最短デプロイ
先にお伝えしますがなんでもテストしないで、何が変更されたのか共有しないで好き勝手に一人でデプロイできるようにしたいという話ではないです。
チームで100、120動けるようになることは素晴らしいが、誰か欠けると1歩すら動けなくなることは好ましい状態じゃないです。
開発者の一つの価値として機能を開発しユーザーさんに届けることで生み出せます。
「変化なくして、進化なし。」とあるように何もしないことは衰退の始まりだと考えています。
そこでどうしたら 開発したものをいかに早くデリバリーできるか を考え実行する
- 中間地点のタッチポイントをいかに減らせるか
- チェックなしでOKということではない
- テストなどの検証を抑える (100%は目指さない)
- QAの観点
- チーム間の仕様の共有は行き届いている状態 (slackなどにポストすればいいという話でも、esaなどのdocsにまとめればいいという話ではない)
- メンバーが何をするべきかわかっている状態
など要点を現時点から中期の状態を想定しチームで考え試していくことが大事だと考えています。
(互いのストロングポイントを活かしながら)
最後に
先月の9月でスナックミーは創立から6年経ちました。snaq.me は来年の3月で丸6年になる予定です。
エンジニアメンバーは今、10名ほどになり少しずつですができることが増えてきています。メンバーが増えると対数的にスピード感や意思決定が遅くなっていく傾向がありますが、早期の段階から取り組むことで良くなると思っています。
また、スタートアップはスピードが命といっても過言ではない、そのため立ち上げ時のスピードをより加速させるためのアプローチはチーム全体で取り組むことで達成できると私は思っています。
これからも定期的にこういう発信はしていこうと思います。
「おやつと、世界を面白く。」 一緒に面白くしたい仲間をお待ちしてます!!