こんにちは!SRE を担当している多田です(@tada_infra).
業務の中で日時を決めて SSM Run Command を実行したい要件がでてきたのでメンテナンスウィンドウを使ってみることにしました.この記事ではメンテナンスウィンドウを AWS CLI を使って設定して行ったメモを備忘録として書いていきます.
メンテナンスウィンドウとは
メンテナンスウィンドウは Systems Manager 関連のサービスで期間や日時を指定したりしてタスクを実行することができます.サポートされているタスクタイプは次の4つです.
- Systems Manager Run Command コマンド
- Systems Manager オートメーションワークフロー
- AWS Lambda 関数
- AWS Step Functions タスク
docs.aws.amazon.com
1. メンテナンスウィンドウの作成
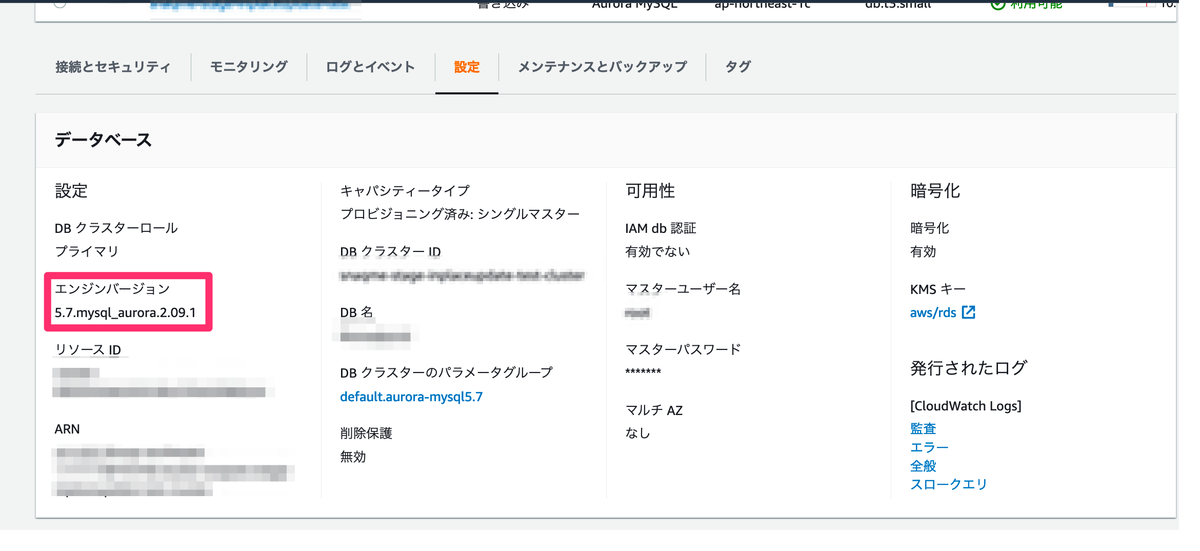
メンテナンスウィンドウは create-maintenance-window で作っていきます.レスポンスで返ってきているWindowsIdがメンテナンスウィンドウを識別する ID です.2時間の間5分毎にタスクを実行するメンテナンスウィンドウになっています.
aws ssm create-maintenance-window \
--name "test-maintenance-window" \
--schedule "rate(5 minutes)" \
--duration 2 \
--cutoff 1 \
--allow-unassociated-targets
{
"WindowId": "mw-xxxx"
}
2. メンテナンスウィンドウでターゲットの登録
メンテナンスウィンドウのタスク実行先(ターゲット)を設定していくには register-target-with-maintenance-window を使います.EC2 に対してコマンドを実行したいのでそのようなパラメータになっています.
aws ssm register-target-with-maintenance-window \
--window-id "mw-xxxx" \
--resource-type "INSTANCE" \
--target "Key=InstanceIds,Values=i-xxx"
{
"WindowTargetId": "xxxx-xxxx-xxxx-xxxx-xxxx"
}
3. ターゲットに対して実行するタスクの登録
メンテナンスウィンドウとターゲットの登録が完了したので,ターゲットに実行したいタスクを登録していきます.Run Command を登録したいので register-task-with-maintenance-window を使って登録します.lsコマンドを実行するだけのタスクを登録しました.
aws ssm register-task-with-maintenance-window \
--window-id mw-xxx \
--task-arn "AWS-RunShellScript" \
--max-concurrency 1 --max-errors 1 \
--priority 10 \
--targets "Key=InstanceIds,Values=i-xxxx" \
--task-type "RUN_COMMAND" \
--task-invocation-parameters '{"RunCommand":{"Parameters":{"commands":["ls"]}}}'
{
"WindowTaskId": "xxxx-xxxx-xxxx-xxxx-xxxx"
}
タスクの実行状況はdescribe-maintenance-window-executionsで確認できます.確認したみたところ,SUCCESSステータスになっているので問題なさそうです.
aws ssm describe-maintenance-window-executions \
--window-id mw-xxxx
{
"WindowExecutions": [
{
"WindowId": "mw-xxxx",
"WindowExecutionId": "xxxx-xxxx-xxxx-xxxx-xxxx",
"Status": "SUCCESS",
"StartTime": "2021-03-07T22:52:36.863000+09:00",
"EndTime": "2021-03-07T22:52:43.710000+09:00"
},
{
"WindowId": "mw-xxxx",
"WindowExecutionId": "xxxx-xxxx-xxxx-xxxx-xxxx",
"Status": "SUCCESS",
"StatusDetails": "No tasks to execute.",
"StartTime": "2021-03-07T22:47:36.990000+09:00",
"EndTime": "2021-03-07T22:47:37.026000+09:00"
},
{
"WindowId": "mw-xxxx",
"WindowExecutionId": "xxxx-xxxx-xxxx-xxxx-xxxx",
"Status": "SUCCESS",
"StatusDetails": "No tasks to execute.",
"StartTime": "2021-03-07T22:42:36.936000+09:00",
"EndTime": "2021-03-07T22:42:36.969000+09:00"
},
{
"WindowId": "mw-xxxx",
"WindowExecutionId": "xxxx-xxxx-xxxx-xxxx-xxxx",
"Status": "SUCCESS",
"StatusDetails": "No tasks to execute.",
"StartTime": "2021-03-07T22:37:36.723000+09:00",
"EndTime": "2021-03-07T22:37:36.758000+09:00"
}
]
}
4. メンテナンスウィンドウの時間を更新する
このままだと5分に一回コマンドが実行され続けるので時間部分を更新しておきます.今回は一度だけ実行したいメンテナンスウィンドウに更新したいのでat(UTC時間)で日時を指定してみます.メンテナンスウィンドウを更新するには update-maintenance-windowを使います.日本時間の2021/03/07 23:00の日時を指定しています.
aws ssm update-maintenance-window \
--window-id mw-xxxx \
--schedule "at(2021-03-07T14:00:00)"
{
"WindowId": "mw-xxxx",
"Name": "test-maintenance-window",
"Schedule": "at(2021-03-07T14:00:00)",
"Duration": 2,
"Cutoff": 1,
"AllowUnassociatedTargets": true,
"Enabled": true
}
実行状況を確認してみます.23時にタスクが実行されていました.
aws ssm describe-maintenance-window-executions \
--window-id mw-xxxx
{
"WindowExecutions": [
{
"WindowId": "mw-xxxx",
"WindowExecutionId": "xxxx-xxxx-xxxx-xxxx-xxxx",
"Status": "SUCCESS",
"StartTime": "2021-03-07T23:00:17.287000+09:00",
"EndTime": "2021-03-07T23:00:23.046000+09:00"
},
{
"WindowId": "mw-xxx",
"WindowExecutionId": xxxx-xxxx-xxxx-xxxx-xxxx",
"Status": "SUCCESS",
"StartTime": "2021-03-07T22:57:36.885000+09:00",
"EndTime": "2021-03-07T22:57:42.674000+09:00"
},
まとめ
AWS CLI を使ってメンテナンスウィンドウを登録して Run Command を実行できるようにしてみました.Systems Manager の活用を進めており,Run Command や処理をまとめた Document,Automation を使うため Systems Manager ファミリーを使い慣れておきたく今回使ってみました.定型処理はまとめてしまってメンテナンスウィンドウを活用していきたいと思います.
元記事
元記事はこちらです.
最後に
そんなスナックミーではもりもりコードを改善し、開発していきたいバックエンドエンジニア、テックリードを募集中です。
採用の最新情報はこちらにありますので、ご興味ある方はご確認ください!
engineers.snaq.me