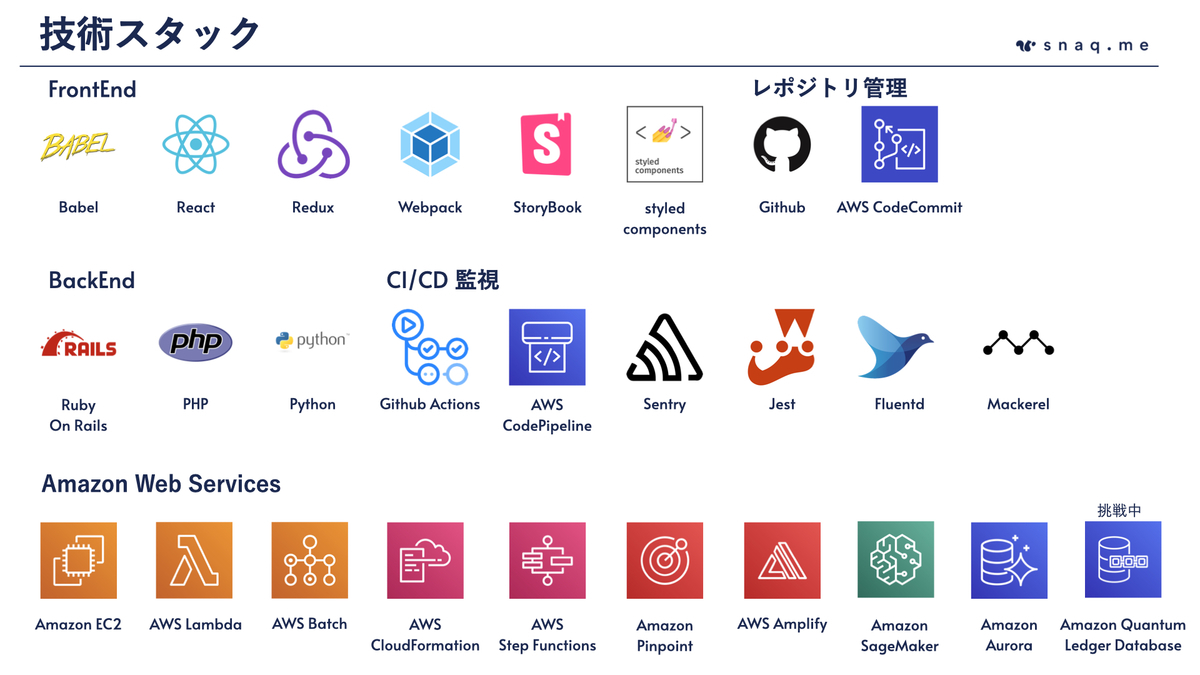
こんにちは!SRE を担当している多田です(@tada_infra).
Lambda のアップデートで昨年の re:Invent でコンテナがサポートされました.
自前のコンテナイメージを実行できるならカスタムランタイムで設定している Lambda の処理をコンテナイメージ化してみようと思い,下記の記事でカスタムランタイムで実行していた Lambda をコンテナイメージ化して変更してみました.この記事で対応内容を書いていきます.
Lambda のカスタムランタイムでやっていた処理をコンテナイメージ化して置き換えてみた
— Sadayoshi Tada🎉 (@tada_infra) 2021年1月25日
コンテナサポート対応設定
実行環境のコンテナは ECR に格納する必要があり,これまでとの違いは Dokcerfile を用意する必要がある点です.AWS から Lambda のコンテナイメージが提供されており,そのイメージを使っていきます.
サポートされているすべての Lambda ランタイム (Python、Node.js、Java、.NET、Go、Ruby) のベースイメージを提供しているため、コードと依存関係を簡単に追加することができます。Amazon Linux ベースのカスタムランタイム用のベースイメージも用意しており、これを拡張して Lambda ランタイム API を実装する独自のランタイムを含めることができます。
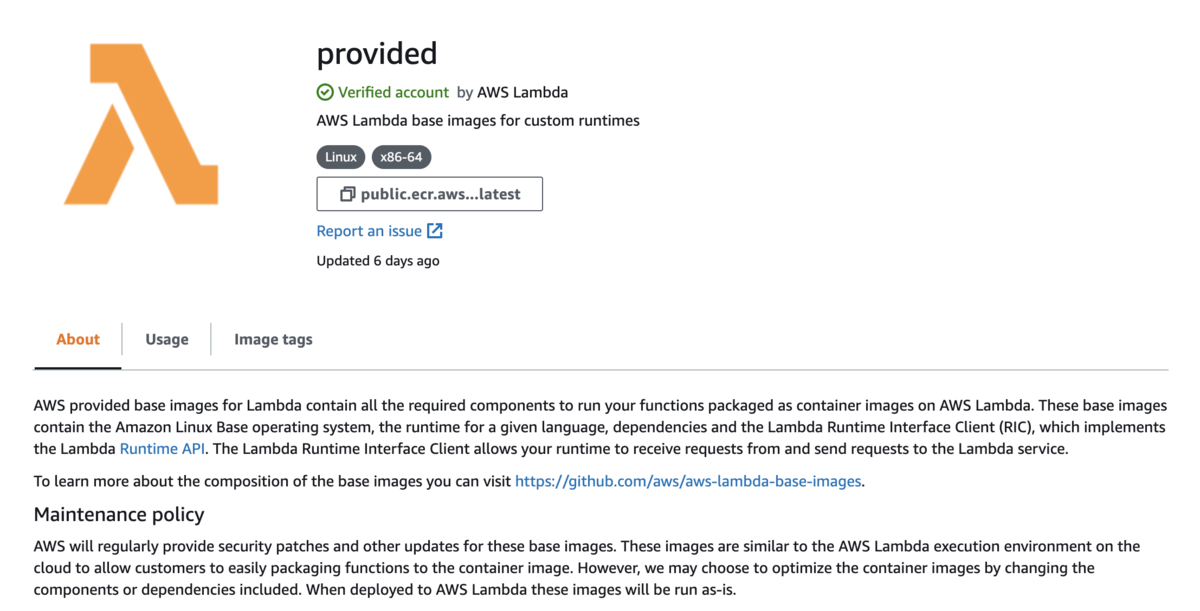
ECR に格納する Dockerfile を次のように定義しました.AWS CLI を使った処理を行ったので AWS CLI を入れて,カスタムランタイムで使っていた bootstrap とカスタムランタイムの関数内で書いていたロジックをスクリプト化して実行するようにしました.
Dockerfile
FROM public.ecr.aws/lambda/provided:latest RUN yum install -y awscli COPY bootstrap /var/runtime/bootstrap COPY xxx.sh /var/runtime/xxx.sh RUN chmod 755 /var/runtime/bootstrap /var/runtime/xxx.sh CMD ["xxx.handler"]
bootstrap
#!/bin/sh set -euo pipefail # Initialization - load function handler source $LAMBDA_TASK_ROOT/"$(echo $_HANDLER | cut -d. -f1).sh" # Processing while true do HEADERS="$(mktemp)" # Get an event. The HTTP request will block until one is received EVENT_DATA=$(curl -sS -LD "$HEADERS" -X GET "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/next") # Extract request ID by scraping response headers received above REQUEST_ID=$(grep -Fi Lambda-Runtime-Aws-Request-Id "$HEADERS" | tr -d '[:space:]' | cut -d: -f2) # Run the handler function from the script RESPONSE=$($(echo "$_HANDLER" | cut -d. -f2) "$EVENT_DATA") # Send the response curl -X POST "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/$REQUEST_ID/response" -d "$RESPONSE" done
ECR にコンテナイメージをプッシュする
コンテナイメージを ECR に格納していきます.ECR で表示するコマンドを順次実行していきます.
# ECR ログイン aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin xxx.dkr.ecr.ap-northeast-1.amazonaws.com # Dockerfile のビルド docker build -t xxx . # タグつけ docker tag xxx:latest xxx.dkr.ecr.ap-northeast-1.amazonaws.com/xxx:latest # イメージのプッシュ docker push xxx.dkr.ecr.ap-northeast-1.amazonaws.com/xxx:latest
Lambda 関数の設定
ECR にコンテナイメージを格納できたら Lambda 関数を作っていきます.これまでの差異は関数作成時にコンテナイメージを選択することです.前の工程でプッシュしたイメージのlatestバージョンを選択して,他の設定を行って Lambda 関数をデプロイします.
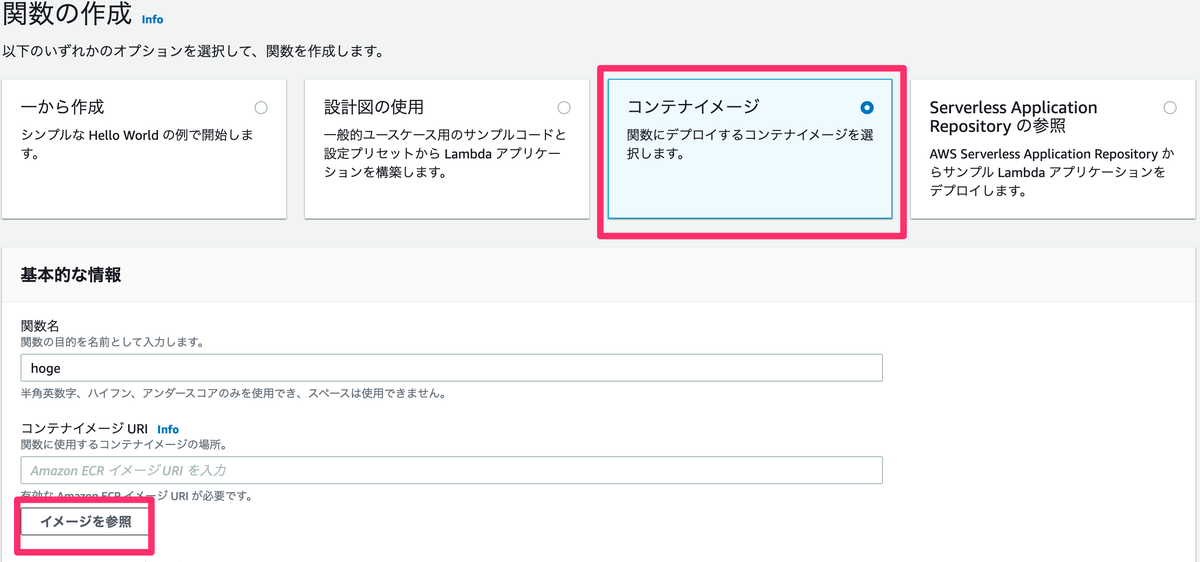
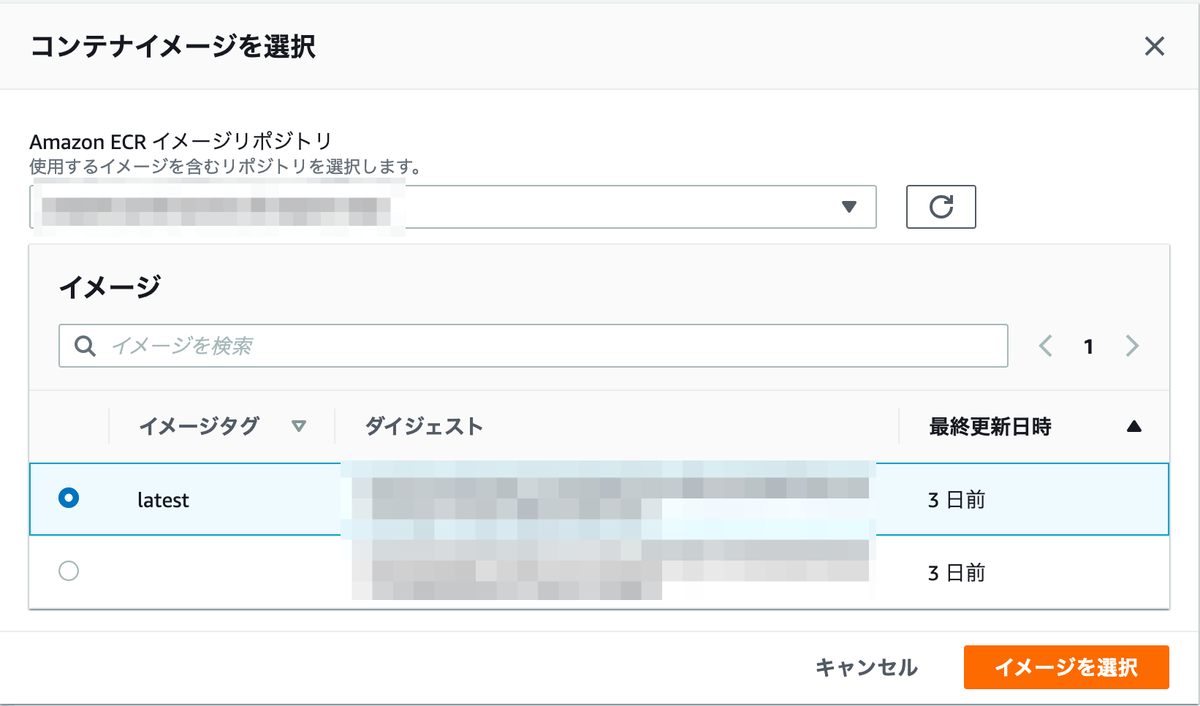
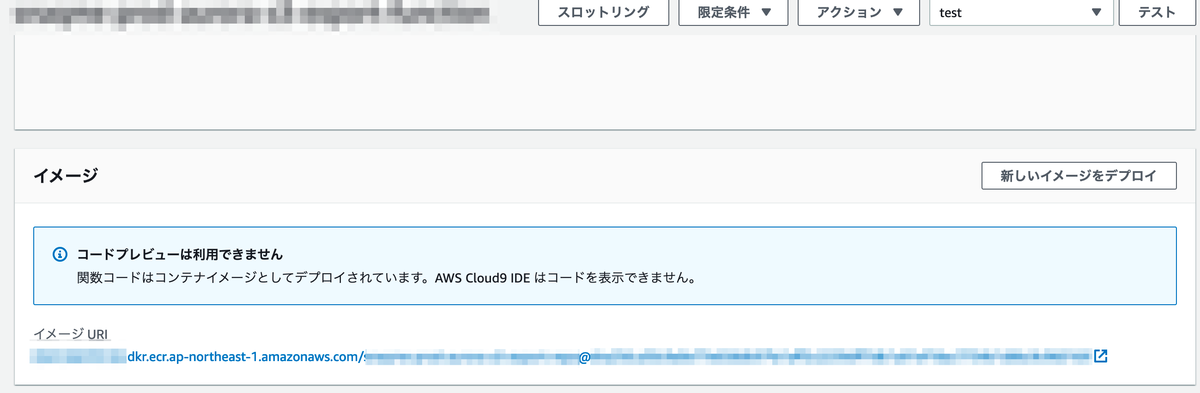
デプロイ後のコード部分を見に行くとコンテナイメージがデプロイされているからコードは見えない仕様になっています.イベント発火後の処理をコンテナ内で設定しておけばこれまで通りカスタムランタイムの Lambda で実行していたのと同様の処理を実行できました.
まとめ
カスタムランタイムの Lambda をコンテナイメージに置き換えたのでその対応をまとめました.カスタムランタイムの Lambda をデプロイするのに Lambda Layer の設定が必要でコードの他にも管理するものがありましたが,コンテナイメージをメンテするだけで同じことができるようになったのは管理範囲が狭まりました.開発時にコンテナイメージを使って開発しているのであれば,開発・デプロイがしやすいのかと思いました.自社でも普及していきたいと思います.
元記事
元記事はこちらです.
最後に
そんなスナックミーではもりもりコードを改善し、開発していきたいバックエンドエンジニア、テックリードを募集中です。 採用の最新情報はこちらにありますので、ご興味ある方はご確認ください!