こんにちは! SRE を担当している多田です(@tada_infra).
リモートワークが広がる中で AWS Client VPN を使って各種業務システムへの接続を検証する必要があり,AWS Client VPN を検証したので何記事かに分けて検証した内容をまとめます.この記事で Get Started な内容を書いていきます.既に同様の内容の記事は多くあるのですが,やった内容整理するために記事を書きます.
AWS Client VPN とは
AWS Client VPN は下記引用文のようなサービスです.Client VPN 登場前はインターネット VPN のためにサーバーを用意する必要がありましたが,それが無くなりマネージドサービスして提供されているためスピーディーに使えてかつサーバー運用不要なところがいいなと思っています.
AWS Client VPN は、AWS リソースやオンプレミスネットワーク内のリソースに安全にアクセスできるようにする、クライアントベースのマネージド VPN サービスです。クライアント VPN を使用すると、OpenVPN ベースの VPN クライアントを使用して、どこからでもリソースにアクセスできます。
課金体系
Client VPN の課金対象となるのが下記の2項目です.
| 課金項目 | 課金額 |
|---|---|
| AWS Client VPN エンドポイントアソシエーション | $0.15/時間 |
| AWS Client VPN 接続 | $0.05/時 |
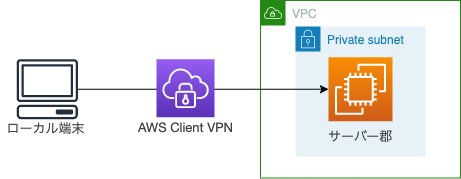
AWS Client VPN を使ってプライベートネットワークにある EC2 に接続する
検証のシナリオとしてプライベートサブネットにある EC2 に Client VPN を使って接続してみます.
Client VPN では認証方式が3つあり,AD 認証,SAML 認証,相互認証があります.今回は相互認証,サーバーとクライアント間で証明書認証を行います.証明書は ACM に登録しておきます.
相互認証では、クライアント VPN は証明書を使用してクライアントとサーバー間の認証を実行します。証明書とは、認証機関 (CA) によって発行された識別用デジタル形式です。クライアントがクライアント VPN エンドポイントに接続を試みると、サーバーはクライアント証明書を使用してクライアントを認証します。サーバー証明書とキー、および少なくとも 1 つのクライアント証明書とキーを作成する必要があります。
サーバーおよびクライアント証明書とキーの生成
サーバーおよびクライアント証明書とキーの作成を行いますが,ドキュメントに記載のフローで対応してきます.キーの作成には easy-rsa を使用します.
$ git clone https://github.com/OpenVPN/easy-rsa.git $ cd easy-rsa/easyrsa3 $ ./easyrsa init-pki #PKI 環境を初期化 init-pki complete; you may now create a CA or requests. Your newly created PKI dir is: /XXXX/XXXX/easy-rsa/easyrsa3/pki $ ./easyrsa build-ca nopass #新しい認証機関 (CA) を構築 Using SSL: openssl LibreSSL 2.8.3 Generating RSA private key, 2048 bit long modulus ......................................................................................+++ ..............................................+++ e is 65537 (0x10001) You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Common Name (eg: your user, host, or server name) [Easy-RSA CA]:awsclient-vpn #任意の名前を入力 CA creation complete and you may now import and sign cert requests. Your new CA certificate file for publishing is at: /XXXX/XXXX/easy-rsa/easyrsa3/pki/ca.crt $ ./easyrsa build-server-full server nopass # Using SSL: openssl LibreSSL 2.8.3 Generating a 2048 bit RSA private key ................................................+++ .............................................................+++ writing new private key to '/XXXX/XXXX/easy-rsa/easyrsa3/pki/easy-rsa-12050.LbZL9a/tmp.B8ySWj' ----- Using configuration from /XXXX/XXXX/easy-rsa/easyrsa3/pki/easy-rsa-12050.LbZL9a/tmp.EXwFe7 Check that the request matches the signature Signature ok The Subject's Distinguished Name is as follows commonName :ASN.1 12:'server' Certificate is to be certified until Mar 26 06:03:31 2023 GMT (825 days) Write out database with 1 new entries Data Base Updated $ ./easyrsa build-client-full client1.domain.tld nopass Using SSL: openssl LibreSSL 2.8.3 Generating a 2048 bit RSA private key ....+++ ............................+++ writing new private key to '/XXXX/XXXX/easy-rsa/easyrsa3/pki/easy-rsa-10663.vj9o3i/tmp.7GLYfD' ----- Using configuration from /XXXX/XXXX/easy-rsa/easyrsa3/pki/easy-rsa-10663.vj9o3i/tmp.TXc5fX Check that the request matches the signature Signature ok The Subject's Distinguished Name is as follows commonName :ASN.1 12:'client1.domain.tld' Certificate is to be certified until Mar 26 04:03:38 2023 GMT (825 days) Write out database with 1 new entries Data Base Updated # 専用のカスタムフォルダーにサーバー及びクライアント証明書をコピーする $ mkdir ~/client_vpn/ $ cp pki/ca.crt ~/client_vpn/ $ cp pki/issued/server.crt ~/client_vpn/ $ cp pki/private/server.key ~/client_vpn/ $ cp pki/issued/client1.domain.tld.crt ~/client_vpn $ cp pki/private/client1.domain.tld.key ~/client_vpn/ $ cd ~/client_vpn/
証明書の ACM へのインポート
作成した証明書を ACM にインポートします.サーバー証明書とクライアント証明書をインポートします.コマンドがうまくいかない場合は画面から直接インポートでも証明書の登録可能です.
$ aws acm import-certificate --certificate fileb://server.crt --private-key fileb://server.key --certificate-chain fileb://ca.crt --region ap-northeast-1 $ aws acm import-certificate --certificate fileb://client1.domain.tld.crt --private-key fileb://client1.domain.tld.key --certificate-chain fileb://ca.crt --region ap-northeast-1
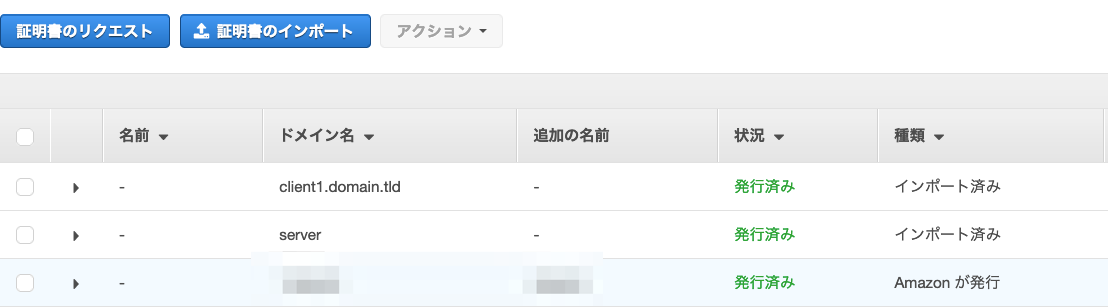
AWS Client VPN 設定を行う
Client VPN を使うための設定を行います.やるのは①クライアント VPN エンドポイント作成,②クライアントの VPN 接続の有効化,③クライアントのネットワークへのアクセスの承認です.
①クライアント VPN エンドポイント作成
クライアントが Client VPN との接続を確立するエンドポイントを作成します.IPアドレスの CIDR は /12~/22 の範囲で指定が必要です.検証用途のため一番小さいサイズで指定しています.また,ACM にインポートしたサーバー及びクライアント証明書を指定します.
IP アドレス範囲は、ターゲットネットワークまたはクライアント VPN エンドポイントに関連するいずれかのルートと重複できません。クライアント CIDR は、/12~/22 の範囲のブロックサイズが必要で、VPC CIDR またはルートテーブル内のその他のルートと重複できません。クライアント VPN エンドポイントの作成後にクライアント CIDR を変更することはできません。
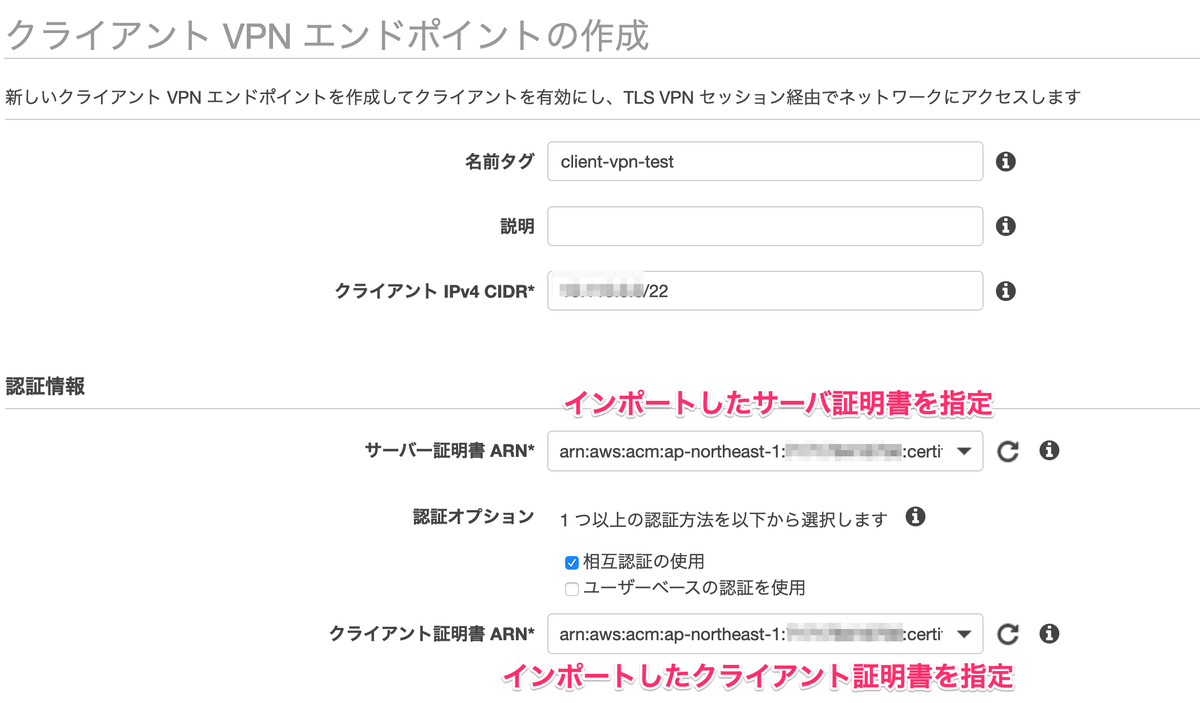
残りとして関連するエンドポイントを紐付ける VPC とセキュリティグループを指定し,それ以外はデフォルト値でエンドポイントの作成を行います.
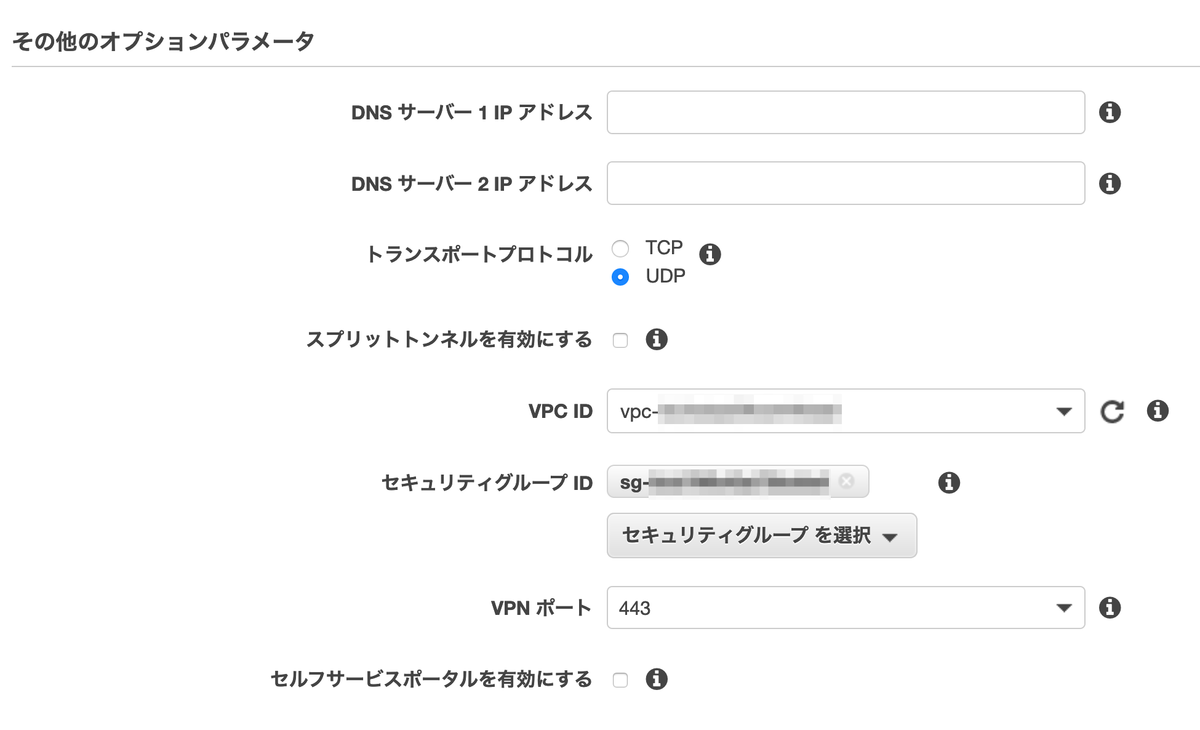
②クライアントの VPN 接続の有効化
次に,クライアントの VPN 接続の有効化を行います.エンドポイントと関連づけるサブネットを指定します.これでエンドポイントが有効化ステータスに遷移したり,ルートテーブルへの設定変更やセキュリティグループの関連付けが行われます.
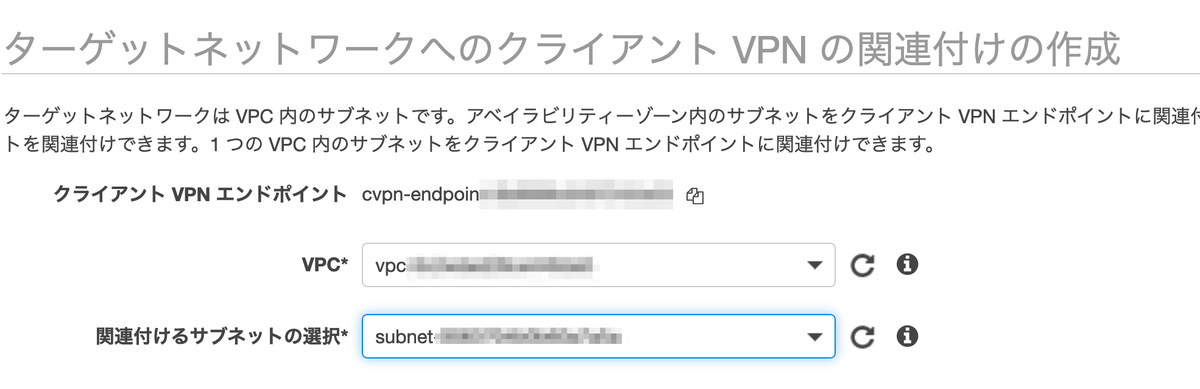
クライアント VPN エンドポイントの状態が available に変わります。これで、クライアントは VPN 接続を確立できるようになりましたが、認証ルールを追加するまで VPC 内のリソースにアクセスすることはできません。
VPC のローカルルートは、クライアント VPN エンドポイントルートテーブルに自動的に追加されます。
VPC のデフォルトのセキュリティグループが、サブネットの関連付けに自動的に適用されます。
しばらくエンドポイント有効化までに時間を要するので待ちます.
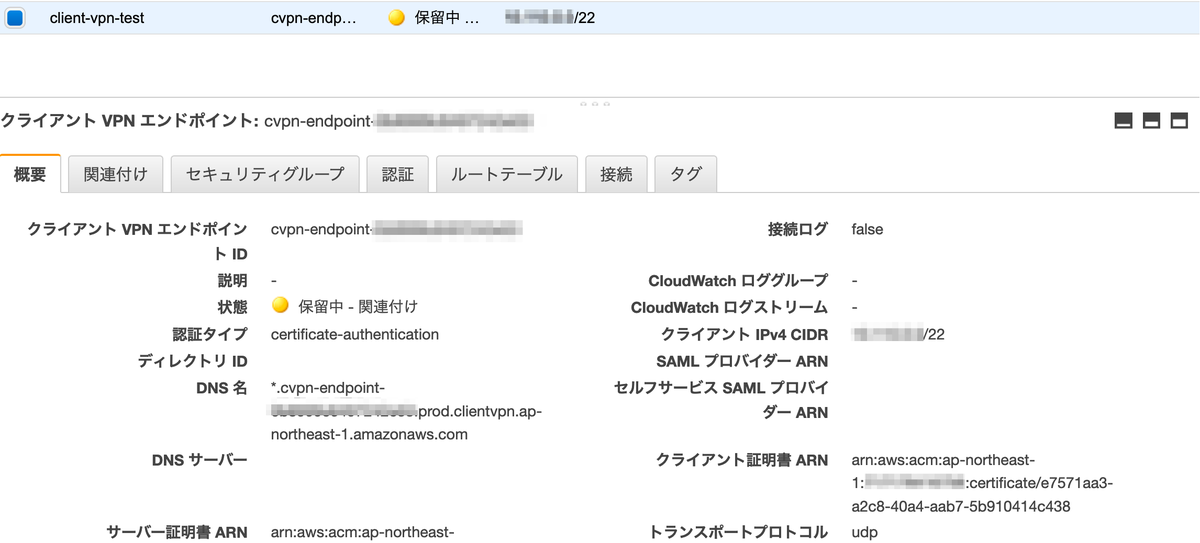
③クライアントのネットワークへのアクセスの承認
そして,クライアントのネットワークへのアクセスの承認を行います.クライアントがアクセスできるサブネットの承認ルールを作成します.ユーザーは誰でもつなげるようにしておき,接続できるネットワークは EC2 がいる VPC の CIDR ブロックを指定しています.
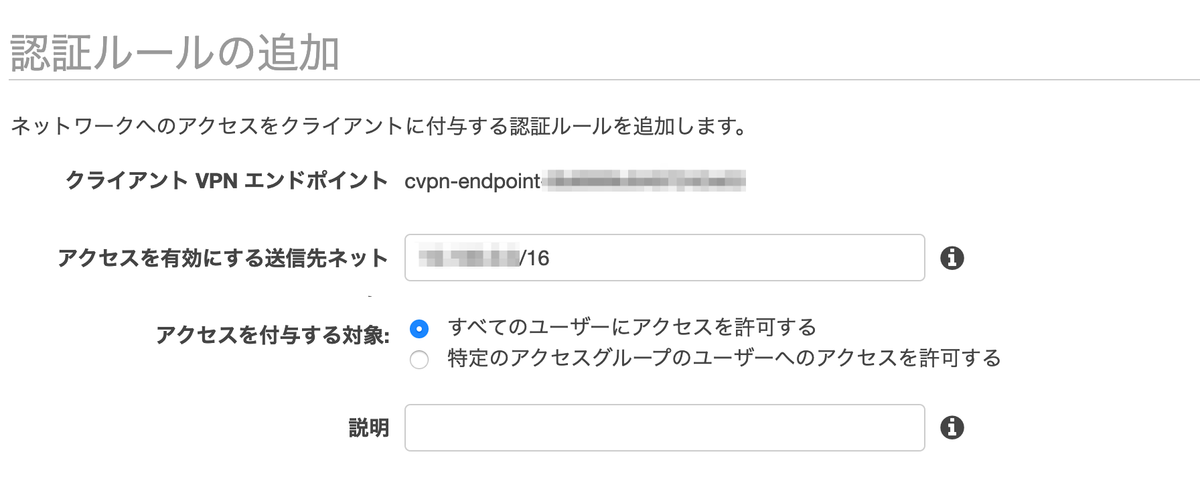
VPN クライアント端末のセットアップ
Client VPN の設定は以上で,次に VPN クライアント側の設定をします.やるのは①クライアントアプリのインストール,②Client VPN 設定の取り込みです.
①クライアントアプリのインストール
AWS から専用のクライアントアプリが Windows/Mac それぞれで提供されているので下記のサイトからダウンロード,インストールします.
自分は Mac なのでアプリケーションアイコンとして次のものができていました.

②Client VPN 設定の取り込み
次に,Client VPN 設定の取り込みを行います.Client VPN 画面から クライアント設定のダウンロード ボタンから設定ファイルをダウンロードすると,downloaded-client-config.ovpn というファイルが保存されます.ダウンロードしたファイルをエディターで開き,末尾にクライアント証明書の情報を転記します.
<cert> Contents of client certificate (.crt) file </cert> <key> Contents of private key (.key) file </key>
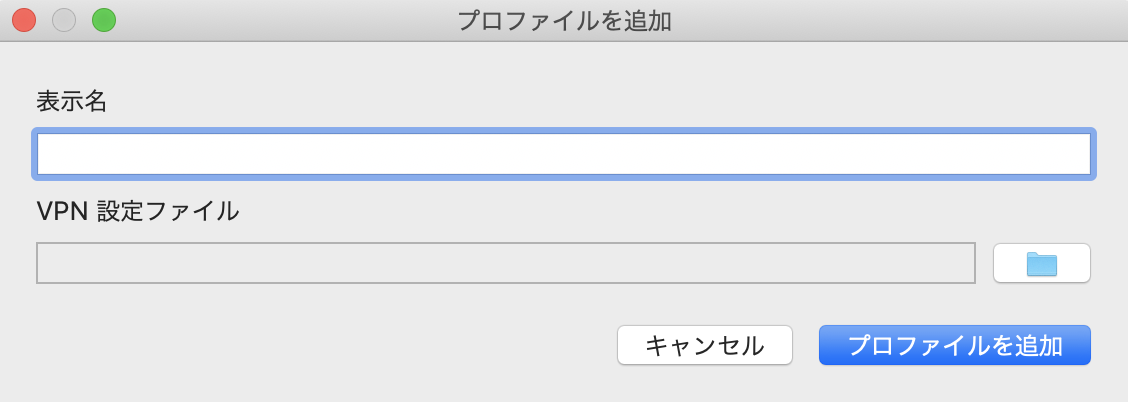
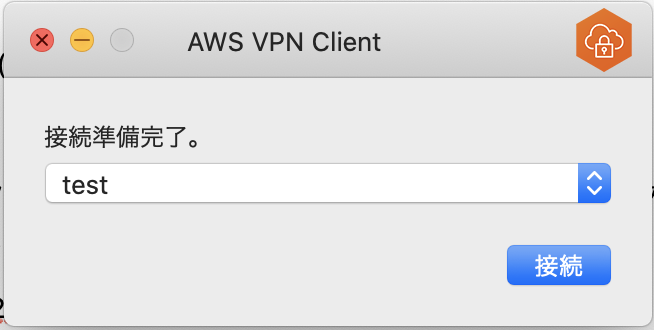
VPN クライアントに設定ファイルを取り込むためにはプロファイルを管理 > プロファイルを追加 していきます.接続名は任意のもの(今回は test というプロファイル名にしました)にし,VPN 設定ファイルはダウンロードした設定ファイルを指定します.これで AWS との接続する準備が整いました.
サーバーへの接続テスト
いよいよプライベートサブネットのサーバーに繋いでみます.サーバーの IP アドレスは XXX.XXX.2.163になります.VPN を経由して SSH で繋いでみましょう.VPN 接続後に端末の IP アドレスを確認すると Client VPN エンドポイントに割り当てたネットワークのアドレスが振られていました.
% ifconfig ~中略~ utun2: flags=8051<UP,POINTOPOINT,RUNNING,MULTICAST> mtu 1500 inet XXX.XXX.0.2 --> XXX.XXX.0.2 netmask 0xffffffe0
そして,対象のサーバーにも SSH できました!
% ssh -i .ssh/XXX.pem XXX@XXX.XXX.2.163 Last login: Mon Dec 21 07:04:45 2020 from XXX.XXX.2.45 XXX@ip-XXX-XXX-2-163:~$ XXX@ip-XXX-XXX-2-163:~$ exit
まとめ
まずは Client VPN をつかってプライベートサブネットの EC2 に接続することをやりました.次は Client VPN をプライベートサブネットにある EC2 にもつなぎつつ他システムで IP アドレスを制御するためグローバル IP アドレスを付与しつつ Client VPN を使う検証を行った内容をまとめます.
元記事
元記事はこちらです.
最後に
そんなスナックミーではもりもりコードを改善し、開発していきたいバックエンドエンジニア、テックリードを募集中です。 採用の最新情報はこちらにありますので、ご興味ある方はご確認ください!